1 교시
** HTML Parsing
=> 웹 사이트에 데이터가 출력은 되어 있는데 Open API 형태로 데이터는 제공하지 않는 경우게 이 데이터를 사용하고자 하면 HTML을 가져와서 핑요한 데이터만 추출해야 하는데 이 것을 HTML Parsing이라고 한다.
최근에는 Web Crawling이라고 하는 경우가 많다.
=> 사용하는 라이브러리는 Jsoup : Python의 BeautifulSoup 라이브러리와 유사
1. Jsoup를 사용한 파싱
Jsoup.parse(html 문자열) : 문자열을 트리 형태로 메모리에 펼치고 메소드들을 이용해서 원하는 DOM을 찾을 수 있도록 해준다.
1) DOM 을 찾기 위한 속성
=> tag : HTML 문서의 구조를 나타내기 위한 명령어로 중복될 수 있다.
=> id : 하나의 DOM을 구분하기 위해서 태그에 붙인 식별자(중복될 수 없다.)
=> class : 여러 DOM에 동일한 디자인을 적용하기 위한 이름으로 중복 될 수 있다.
=> name : 서버에게 데이터를 전달할 때 서버에서 인식할 이름으로 중복 될 수 있다.
=> selector : DOM을 다양한 방법으로 선택하기 위한 문법으로 중복 될 수 있다.
hQuery 와 같은 javascript 라이브러리를 학습할 때 중요
=> xpath : XML에서 각각의 DOM을 찾아가기 위한 언어로 중복될 수 없다.
Macro와 같은 웹 페이지 자동화를 위한 응용프로그램 작성에서 중요
selector
body > div.contentWrapper > div.container > div.left_cont > div > div:nth-child(1) > div.news_head > h1
xpath
/html/body/div[5]/div[1]/div[1]/div/div[1]/div[1]/h1
2) DOM을 찾기 위한 메소드
=> getElementById(String id)
=> getElementsByTagName(String tag)
=> getElementsByClass(String class)
=> select(String selector)
위의 메소드를 호출하면 Element 나 Element의 List인 Elements를 리턴
3) Element의 메소드
=> text() : 태그 안의 문자열이 리턴
=> attr(String attribute) : 태그 안의 attribute의 값을 문자열로 리턴
2~3 교시
2. 기사 가져오기
1) HTML Parsing 을 위한 라이브러리의 의존성을 설정 - pon.xml 파일에 작성
| https://mvnrepository.com/ |
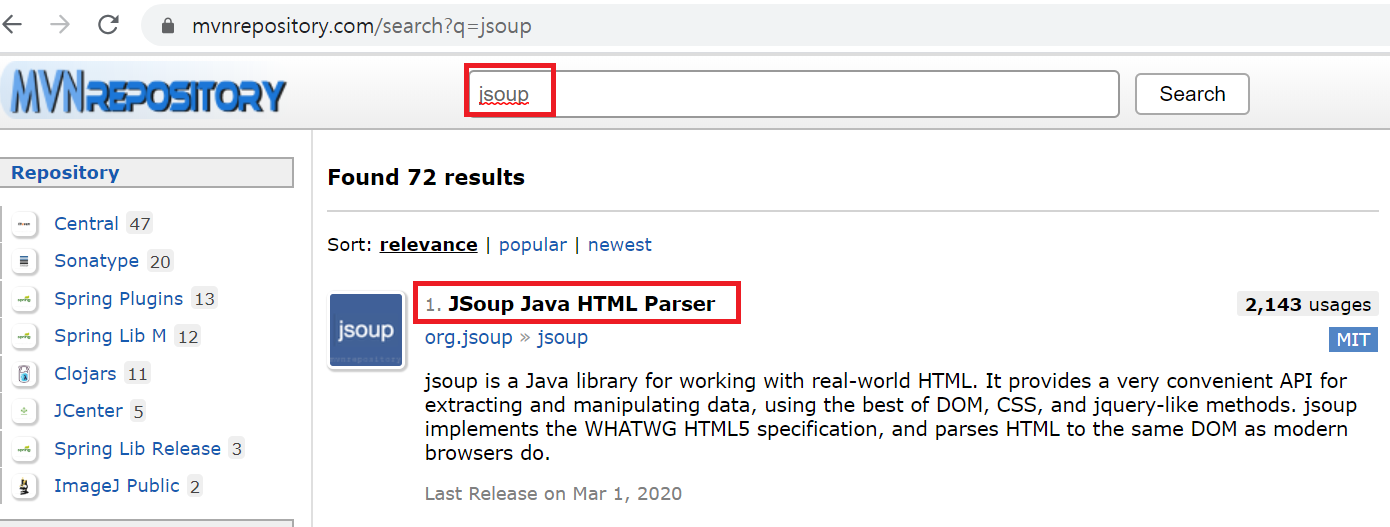 |
 |
 |
 |
2) 데이터를 다운로드받는 코드를 main 메소드에 추가
String html = null;
try {
//URL 만들기 - 파라미터에 한글이 있으면 파라미터를 인코딩 파라미터는 ? 다음에 나오는 문자열
String addr = "http://www.hani.co.kr/";
URL url = new URL(addr);
//연결 객체 만들기
//header에 추가하는 옵션이 있는지 확인
//header가 있는 경우는 api key 나 id 나 비밀번호를 설정해야 하는 경우
HttpURLConnection con = (HttpURLConnection)url.openConnection();
con.setUseCaches(true);
con.setConnectTimeout(30000);
//스트림을 사용해서 문자열을 읽어오는 부분
//읽었는데 한글이 깨지면 InputStreamReader 생성자에 euc-kr 추가
BufferedReader br = new BufferedReader(new InputStreamReader(con.getInputStream()));
StringBuilder sb = new StringBuilder();
while(true) {
String line = br.readLine();
if(line == null) {
break;
}
sb.append(line + "\n");
}
//문자열을 복사하고 정리
html = sb.toString();
br.close();
con.disconnect();
}catch(Exception e) {
System.out.println("다운로드 실패");
System.out.println(e.getMessage());
e.printStackTrace();
}
3) 다운로드 받은 문자열에서 메인 기사 제목 가져오기
//데이터 확인 - 제대로 읽어왔는지 한글이 깨지는지
//System.out.println(html);
if(html != null && html.trim().length() > 0) {
//문서 구조 가져오기
Document document = Jsoup.parse(html);
//선택자 이용해서 가져오기
Elements elements = document.select(
"#main-top > div.main-top > div.main-top-article > h4 > a");
//선택자를 이용한 것은 반복문을 수행
for(int i=0; i<elements.size(); i=i+1) {
//DOM 1개 가져오기
Element element = elements.get(i);
System.out.println(element.text());
}
}else {
System.out.println("읽어온 데이터가 없음");
}
3. 메인 기사의 링크를 가져오기
=> HTML에서 링크의 구조
<a href="링크">텍스트나 이미지</a>
=> 게시판(신문)이나 SNS 등에서 검색을 하게 되면 제목과 링크가 나온다.
이 경우 링크를 따라가서 실제 데이터를 가져와야 한다.
<a href="https://www.donga.con/news/article/all/20191112/98330512/1" target="_black">[단독]서울대 연구팀, AI로 인체의 근육 움직임 세계 최초 재현</a>
=> 속성의 값을 가져올 때는 text() 대신에 get(String attribute);
System.out.println(element.text());
부분을 수정
System.out.lrintln(element.attr("href"));
4. SNS나 게시판에서 기사가져오기
=> URL의 구조를 잘 파악해야 한다.
=> 링크를 따라가서 기사나 본문의 내용을 가져와야 한다.
=> 첫번째 검색의 결과에서 데이터 개수를 잘 추출해야 한다.
언제까지 수행을 해서 데이터를 가져올 지 결정할 수 있다.
4 교시
5. www.donga.com 에서 박문석으로 검색한 기사들의 내용을 파일에 저장
=> url 패턴을 확인
=> 처음에는 데이터 개수를 찾아야 한다.
=> 데이터 개수를 알면 반복문을 이용해서 검색된 모든 결과에서 데이터를 찾아와야 한다.
1) url 패턴을 확인
https://www.donga.com/news/search?p=16&query=%EB%B0%95%EB%AC%B8%EC%84%9D&check_news=1&more=1&sorting=1&search_date=1&v1=&v2=&range=1
https://www.donga.com/news/search?p=31&query=%EB%B0%95%EB%AC%B8%EC%84%9D&check_news=1&more=1&sorting=1&search_date=1&v1=&v2=&range=1
=> 검색어는 query에 대입
=> 페이지가 변경되면 p파라미터가 15씩 변경
1페이지면 1
2페이지면 16
3페이지면 31
=> 전체 데이터 개수를 이용해서 페이지 개수를 찾아야 한다.
전체 데이터 개수가 15이면 1페이지
전체 데이터 개수가 16이면 2페이지
전체 데이터 개수가 30이면 2페이지
페이지 개수는 전체 데이터 / 페이지당 데이터 개수를 구한 후 %를 해서 나머지가 있으면 +1
// back-end 이건 front-end 이건 계산할 수 있어야 한다.
int pagesu = (int)(전체데이터개수 / 15) + ((double)14/15))
int pagesu = 전체데이터개수 / 15;
if(전체데이터개수 %15 !=0) {
pagesu = pagesu +1;
}
=> 페이지 개수를 찾으면 페이지 번호를 어떻게 대입해야 하는가 계산
MySQL 같은 곳에서 원하는 범위를 데이터를 가져올 때 활용
페이지 번호는 1, 2, 3
p는 1, 16, 31....
15*sing
=> 웹 사이트에 데이터가 출력은 되어 있는데 Open API 형태로 데이터는 제공하지 않는 경우게 이 데이터를 사용하고자 하면 HTML을 가져와서 핑요한 데이터만 추출해야 하는데 이 것을 HTML Parsing이라고 한다.
최근에는 Web Crawling이라고 하는 경우가 많다.
=> 사용하는 라이브러리는 Jsoup : Python의 BeautifulSoup 라이브러리와 유사
1. Jsoup를 사용한 파싱
Jsoup.parse(html 문자열) : 문자열을 트리 형태로 메모리에 펼치고 메소드들을 이용해서 원하는 DOM을 찾을 수 있도록 해준다.
1) DOM 을 찾기 위한 속성
=> tag : HTML 문서의 구조를 나타내기 위한 명령어로 중복될 수 있다.
=> id : 하나의 DOM을 구분하기 위해서 태그에 붙인 식별자(중복될 수 없다.)
=> class : 여러 DOM에 동일한 디자인을 적용하기 위한 이름으로 중복 될 수 있다.
=> name : 서버에게 데이터를 전달할 때 서버에서 인식할 이름으로 중복 될 수 있다.
=> selector : DOM을 다양한 방법으로 선택하기 위한 문법으로 중복 될 수 있다.
hQuery 와 같은 javascript 라이브러리를 학습할 때 중요
=> xpath : XML에서 각각의 DOM을 찾아가기 위한 언어로 중복될 수 없다.
Macro와 같은 웹 페이지 자동화를 위한 응용프로그램 작성에서 중요
selector
body > div.contentWrapper > div.container > div.left_cont > div > div:nth-child(1) > div.news_head > h1
xpath
/html/body/div[5]/div[1]/div[1]/div/div[1]/div[1]/h1
2) DOM을 찾기 위한 메소드
=> getElementById(String id)
=> getElementsByTagName(String tag)
=> getElementsByClass(String class)
=> select(String selector)
위의 메소드를 호출하면 Element 나 Element의 List인 Elements를 리턴
3) Element의 메소드
=> text() : 태그 안의 문자열이 리턴
=> attr(String attribute) : 태그 안의 attribute의 값을 문자열로 리턴
2~3 교시
2. 기사 가져오기
1) HTML Parsing 을 위한 라이브러리의 의존성을 설정 - pon.xml 파일에 작성
https://mvnrepository.com/




2) 데이터를 다운로드받는 코드를 main 메소드에 추가
String html = null;
try {
//URL 만들기 - 파라미터에 한글이 있으면 파라미터를 인코딩 파라미터는 ? 다음에 나오는 문자열
String addr = "http://www.hani.co.kr/";
URL url = new URL(addr);
//연결 객체 만들기
//header에 추가하는 옵션이 있는지 확인
//header가 있는 경우는 api key 나 id 나 비밀번호를 설정해야 하는 경우
HttpURLConnection con = (HttpURLConnection)url.openConnection();
con.setUseCaches(true);
con.setConnectTimeout(30000);
//스트림을 사용해서 문자열을 읽어오는 부분
//읽었는데 한글이 깨지면 InputStreamReader 생성자에 euc-kr 추가
BufferedReader br = new BufferedReader(new InputStreamReader(con.getInputStream()));
StringBuilder sb = new StringBuilder();
while(true) {
String line = br.readLine();
if(line == null) {
break;
}
sb.append(line + "\n");
}
//문자열을 복사하고 정리
html = sb.toString();
br.close();
con.disconnect();
}catch(Exception e) {
System.out.println("다운로드 실패");
System.out.println(e.getMessage());
e.printStackTrace();
}
3) 다운로드 받은 문자열에서 메인 기사 제목 가져오기
//데이터 확인 - 제대로 읽어왔는지 한글이 깨지는지
//System.out.println(html);
if(html != null && html.trim().length() > 0) {
//문서 구조 가져오기
Document document = Jsoup.parse(html);
//선택자 이용해서 가져오기
Elements elements = document.select(
"#main-top > div.main-top > div.main-top-article > h4 > a");
//선택자를 이용한 것은 반복문을 수행
for(int i=0; i<elements.size(); i=i+1) {
//DOM 1개 가져오기
Element element = elements.get(i);
System.out.println(element.text());
}
}else {
System.out.println("읽어온 데이터가 없음");
}
3. 메인 기사의 링크를 가져오기
=> HTML에서 링크의 구조
<a href="링크">텍스트나 이미지</a>
=> 게시판(신문)이나 SNS 등에서 검색을 하게 되면 제목과 링크가 나온다.
이 경우 링크를 따라가서 실제 데이터를 가져와야 한다.
<a href="https://www.donga.con/news/article/all/20191112/98330512/1" target="_black">[단독]서울대 연구팀, AI로 인체의 근육 움직임 세계 최초 재현</a>
=> 속성의 값을 가져올 때는 text() 대신에 get(String attribute);
System.out.println(element.text());
부분을 수정
System.out.lrintln(element.attr("href"));
4. SNS나 게시판에서 기사가져오기
=> URL의 구조를 잘 파악해야 한다.
=> 링크를 따라가서 기사나 본문의 내용을 가져와야 한다.
=> 첫번째 검색의 결과에서 데이터 개수를 잘 추출해야 한다.
언제까지 수행을 해서 데이터를 가져올 지 결정할 수 있다.
4 교시
5. www.donga.com 에서 박문석으로 검색한 기사들의 내용을 파일에 저장
=> url 패턴을 확인
=> 처음에는 데이터 개수를 찾아야 한다.
=> 데이터 개수를 알면 반복문을 이용해서 검색된 모든 결과에서 데이터를 찾아와야 한다.
1) url 패턴을 확인
https://www.donga.com/news/search?p=16&query=%EB%B0%95%EB%AC%B8%EC%84%9D&check_news=1&more=1&sorting=1&search_date=1&v1=&v2=&range=1
https://www.donga.com/news/search?p=31&query=%EB%B0%95%EB%AC%B8%EC%84%9D&check_news=1&more=1&sorting=1&search_date=1&v1=&v2=&range=1
=> 검색어는 query에 대입
=> 페이지가 변경되면 p파라미터가 15씩 변경
1페이지면 1
2페이지면 16
3페이지면 31
=> 전체 데이터 개수를 이용해서 페이지 개수를 찾아야 한다.
전체 데이터 개수가 15이면 1페이지
전체 데이터 개수가 16이면 2페이지
전체 데이터 개수가 30이면 2페이지
페이지 개수는 전체 데이터 / 페이지당 데이터 개수를 구한 후 %를 해서 나머지가 있으면 +1
// back-end 이건 front-end 이건 계산할 수 있어야 한다.
int pagesu = (int)(전체데이터개수 / 15) + ((double)14/15))
int pagesu = 전체데이터개수 / 15;
if(전체데이터개수 %15 !=0) {
pagesu = pagesu +1;
}
=> 페이지 개수를 찾으면 페이지 번호를 어떻게 대입해야 하는가 계산
MySQL 같은 곳에서 원하는 범위를 데이터를 가져올 때 활용
페이지 번호는 1, 2, 3
p는 1, 16, 31....
15*페이지번호 -14
페이지 번호를 가지고 p구하기
어제거 답
for(int i = 0; i<25; i=i+1) {
ar[i/5][i%5];
}
package htmlparsing;
import java.io.BufferedReader;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
import java.net.URLEncoder;
public class DongACrawling {
public static void main(String[] args) {
String html = null;
try {
//URL 만들기 - 파라미터에 한글이 있으면 파라미터를 인코딩 파라미터는 ? 다음에 나오는 문자열
String query = "박문석";
// 파라미터 인코딩
query = URLEncoder.encode(query, "utf-8");
String addr = "https://www.donga.com/news/search?p=16&query="
+ query
+ "&check_news=1&more=1&sorting=1&search_date=1&v1=&v2=&range=1/";
URL url = new URL(addr);
//연결 객체 만들기
//header에 추가하는 옵션이 있는지 확인
//header가 있는 경우는 api key 나 id 나 비밀번호를 설정해야 하는 경우
HttpURLConnection con = (HttpURLConnection)url.openConnection();
con.setUseCaches(true);
con.setConnectTimeout(30000);
//스트림을 사용해서 문자열을 읽어오는 부분
//읽었는데 한글이 깨지면 InputStreamReader 생성자에 euc-kr 추가
BufferedReader br = new BufferedReader(new InputStreamReader(con.getInputStream()));
StringBuilder sb = new StringBuilder();
while(true) {
String line = br.readLine();
if(line == null) {
break;
}
sb.append(line + "\n");
}
//문자열을 복사하고 정리
html = sb.toString();
br.close();
con.disconnect();
}catch(Exception e) {
System.out.println("다운로드 실패");
System.out.println(e.getMessage());
e.printStackTrace();
}
//데이터 확인 - 제대로 읽어왔는지 한글이 깨지는지
System.out.println(html);
}
}
2) 첫번째 페이지의 데이터를 읽어서 검색 건수 찾아오기
package htmlparsing;
import java.io.BufferedReader;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
import java.net.URLEncoder;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
public class DongACrawling {
public static void main(String[] args) {
String html = null;
try {
//URL 만들기 - 파라미터에 한글이 있으면 파라미터를 인코딩 파라미터는 ? 다음에 나오는 문자열
String query = "박문석";
// 파라미터 인코딩
query = URLEncoder.encode(query, "utf-8");
String addr = "https://www.donga.com/news/search?p=16&query="
+ query
+ "&check_news=1&more=1&sorting=1&search_date=1&v1=&v2=&range=1/";
URL url = new URL(addr);
//연결 객체 만들기
//header에 추가하는 옵션이 있는지 확인
//header가 있는 경우는 api key 나 id 나 비밀번호를 설정해야 하는 경우
HttpURLConnection con = (HttpURLConnection)url.openConnection();
con.setUseCaches(true);
con.setConnectTimeout(30000);
//스트림을 사용해서 문자열을 읽어오는 부분
//읽었는데 한글이 깨지면 InputStreamReader 생성자에 euc-kr 추가
BufferedReader br = new BufferedReader(new InputStreamReader(con.getInputStream()));
StringBuilder sb = new StringBuilder();
while(true) {
String line = br.readLine();
if(line == null) {
break;
}
sb.append(line + "\n");
}
//문자열을 복사하고 정리
html = sb.toString();
br.close();
con.disconnect();
}catch(Exception e) {
System.out.println("다운로드 실패");
System.out.println(e.getMessage());
e.printStackTrace();
}
//데이터 확인 - 제대로 읽어왔는지 한글이 깨지는지
//System.out.println(html);
// 데이터 건수를 저장할 변수
int cnt = -1;
try {
// 텍스트를 메모리에 펼치기
Document document = Jsoup.parse(html);
Elements elements = document.select("#content > div.searchContWrap > div.searchCont > h2 > span:nth-child(1)");
for(int i =0; i<elements.size(); i=i+1) {
Element element = elements.get(i);
String content = element.text();
System.out.println(content);
// 기사 건수만 찾아오기
// 공백을 기준으로 분할
String [] ar = content.split(" ");
cnt = Integer.parseInt(ar[1]);
System.out.println(cnt);
}
}catch(Exception e) {
System.out.println("다운로드 실패");
System.out.println(e.getMessage());
e.printStackTrace();
}
}
}
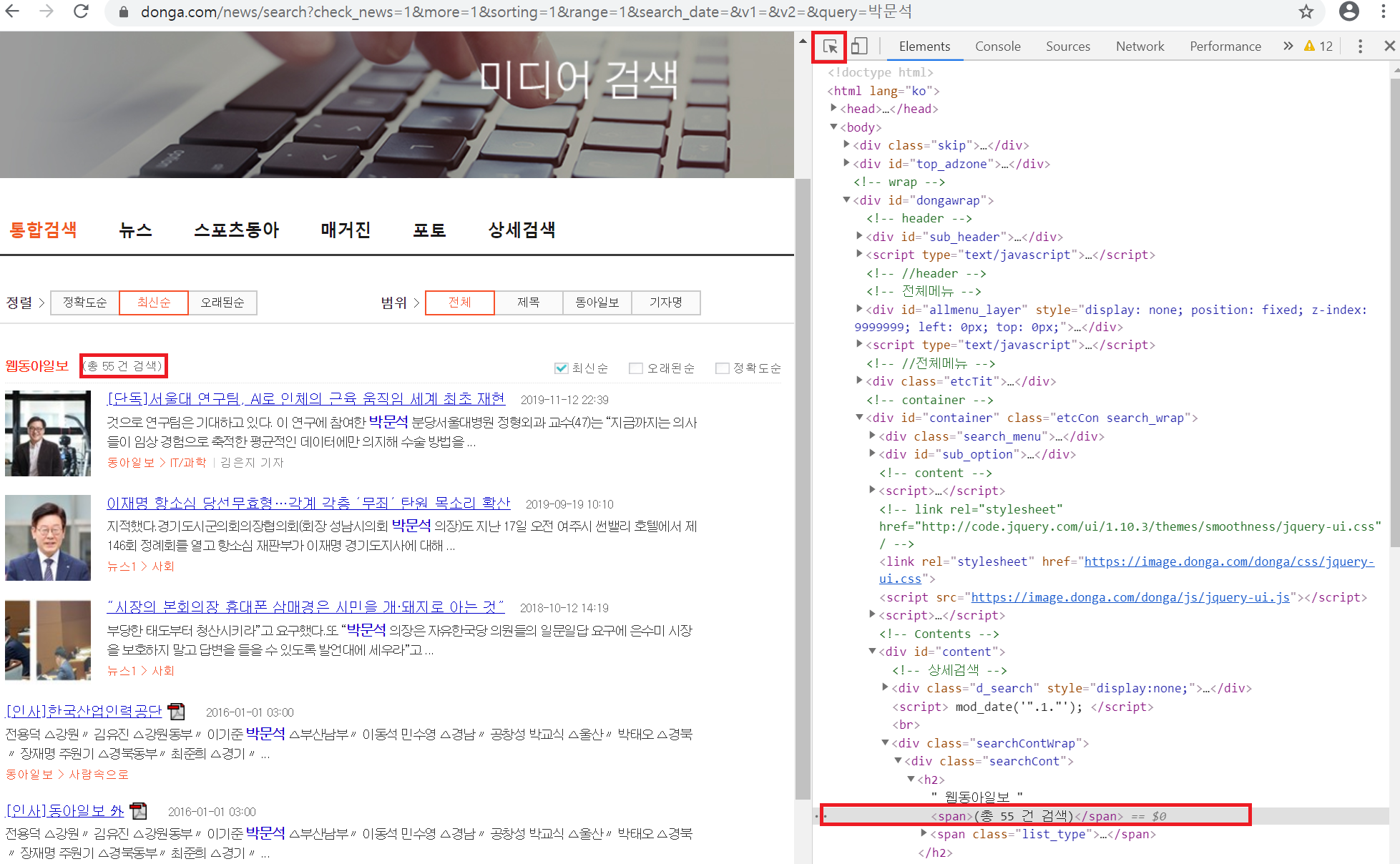 |
 Elements elements = document.select("뒤에 아래 복사된 코드를 붙여넣기"); |
 공백으로 위의 문자열을 나누면 |
5 교시
// 페이지 당 데이터 개수
int perPageCnt = 15;
// 페이지 개수 계산
// 나머지가 있으면 페이지 개수를 1개 추가
int pageCnt = cnt / perPageCnt;
if(cnt % perPageCnt != 0) {
pageCnt = pageCnt +1;
}
System.out.println(pageCnt);
3) 기사의 링크(a 태그의 href 속성) 만 전부 수집
 #content > div.searchContWrap > div.searchCont > div:nth-child(2) > div.t > p.tit > a |
 |
// 기사의 링크를 저장할 변수
List<String> list = new ArrayList<>();
try {
for (int i = 0; i < pageCnt; i = i + 1) {
// 반복문 안에서 예외가 발생했을 때 다음 반복으로 넘어가고자 하면 반복문 안에서 예외처리
try {
String query = "박문석";
// 파라미터 인코딩
query = URLEncoder.encode(query, "utf-8");
String addr = "https://www.donga.com/news/search?p="
+ ((i*perPageCnt) + 1)
+ "&query=" + query
+ "&check_news=1&more=1&sorting=1&search_date=1&v1=&v2=&range=1/";
URL url = new URL(addr);
HttpURLConnection con = (HttpURLConnection)url.openConnection();
con.setUseCaches(false);
con.setConnectTimeout(10000);
BufferedReader br = new BufferedReader(new InputStreamReader(con.getInputStream()));
StringBuilder sb = new StringBuilder();
while(true) {
String line = br.readLine();
if(line == null) {
break;
}
sb.append(line + "\n");
}
html = sb.toString();
br.close();
con.disconnect();
// 다운로드 되었는지 한글은 깨지지 않는지 확인
// System.out.println(html);
// 링크 수집을 위해서 html 파싱
Document doc = Jsoup.parse(html);
// 선택자가 너무 길 때는 앞 쪽은 생략해도 된다.
Elements elements = doc.select("#content > div.searchContWrap"
+ " > div.searchCont > div:nth-child(2) > div.t > p.tit > a");
for(int j=0; j<elements.size(); j=j+1) {
Element element = elements.get(j);
// a 태그의 href 속성을 list에 저장
list.add(element.attr("href"));
}
//System.out.println(list);
}catch(Exception e){
System.out.println("현재 페이지 읽어오기 실패");
System.out.println(e.getMessage());
e.printStackTrace();
}
}
4) 기사 링크를 전부 순회하면서 기사 내용을 파일에 저장
// 현재 디렉토리에 박문석.txt 파일에 기사 내용 저장
// try() 안에 만든 객체는 close를 호출할 필요가 없다
try (PrintWriter pw = new PrintWriter("./박문석.txt")) {
for (String link : list) {
try {
URL url = new URL(link);
HttpURLConnection con = (HttpURLConnection) url.openConnection();
con.setUseCaches(false);
con.setConnectTimeout(10000);
BufferedReader br = new BufferedReader(new InputStreamReader(con.getInputStream()));
StringBuilder sb = new StringBuilder();
while (true) {
String line = br.readLine();
if (line == null) {
break;
}
sb.append(line + "\n");
}
html = sb.toString();
br.close();
con.disconnect();
//System.out.println(html);
// 기사 내용만 골라서 파일에 저장
Document document = Jsoup.parse(html);
Elements elements = document.select("#content > div > div.article_txt > div:nth-child(5)");
for(int k=0; k<elements.size(); k=k+1) {
Element element = elements.get(k);
pw.print(element.text());
pw.flush();
}
} catch (Exception e) {
System.out.println("기사 가져오기 실패");
System.out.println(e.getMessage());
e.printStackTrace();
}
}
} catch (Exception e) {
System.out.println("기사 링크 저장 실패");
System.out.println(e.getMessage());
e.printStackTrace();
} 태그들이 삭제되고 기사 내용만 남는다. |
6~7 교시
** selenium
=> Selenium은 웹 앱을 테스트하는데 이용하는 프레임워크
=> Webdriver 라는 API를 통해 운영체제에 설치된 브라우저를 제어
1. Web 문서를 스크래핑할 때 그냥은 스크래핑이 안되는 데이터
=> ajax(Asynchronous JAvascript Xml - 비동기적으로 자바스크립트를 이용해서 가져오는 XML)를 이용해서 가져온 데이터
=> 로그인 해야 접속이 가능한 페이지
=> 자바스크립트의 이벤트를 이용해서 가져오는 데이터
2. 1번과 같은 데이터들은 브라우저를 직접 구동시켜서 동작을 수행하도록 해서 가져올 수 있다.
=> 이러한 작업을 수행할 수 있도록 만들어진 라이브러리가 selenium이다.
3. 준비
=> 제어하고자 하는 웹 브라우저의 드라이버 : 자신의 브라우저 버전과 드라이버 버전이 맞아야 한다.
=> selenium을 자바에서 구동하기 위한 라이브러리
1) 브라우저 드라이버 다운로드
=> 구글 검색창에 브라우저 드라이버로 검색
전 83.0.4103.61(공식 빌드) (64비트)
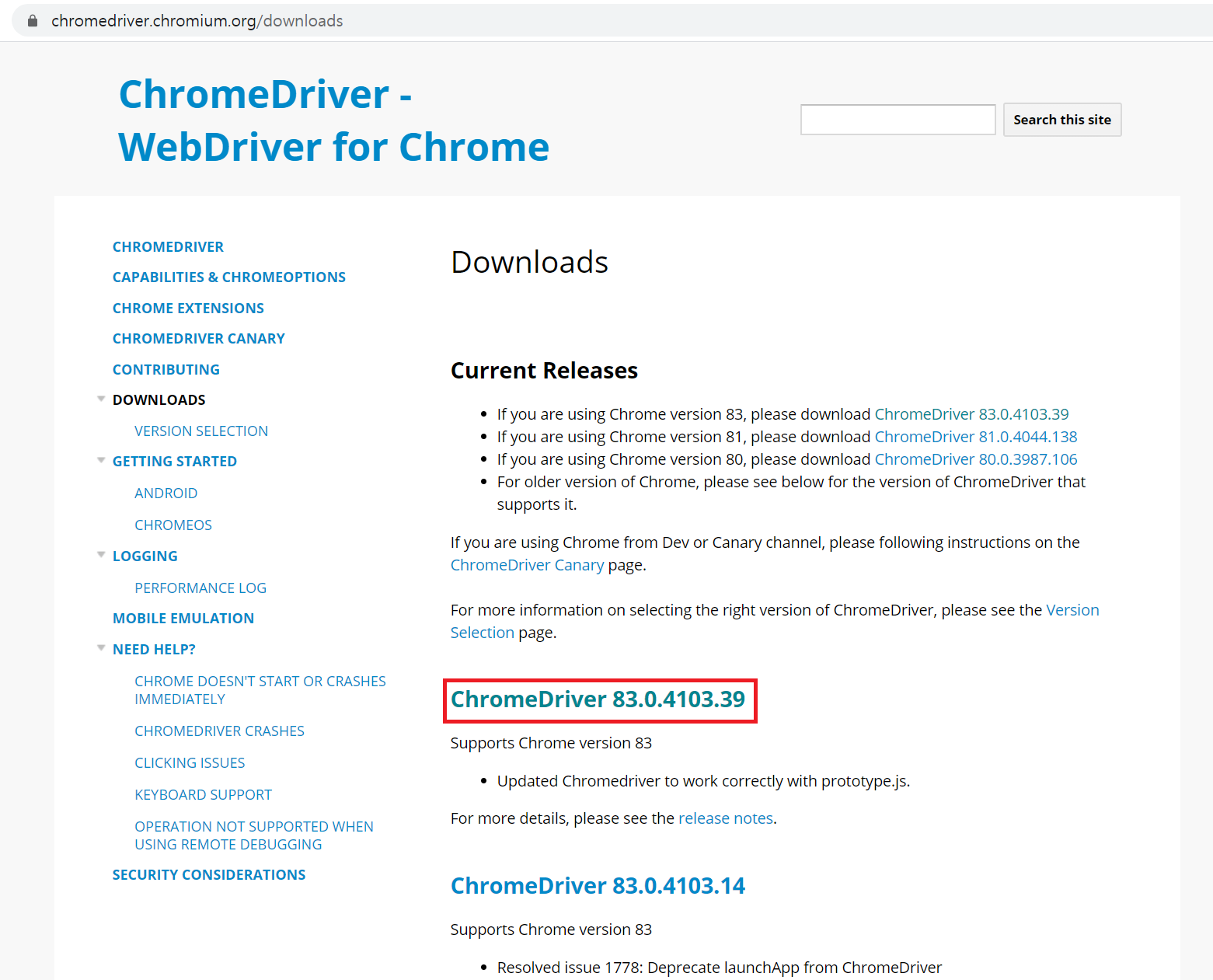 운영체제에 맞게 다운로드하고 자바 프로텍트가 저장되는 디렉토리에 저장해두자. |
2. Selenium 드라이버 다운로드
stable : 안정화 버전
debug : 테스트 하면서 실행 - 테스트 판
release : 실행 - 배포판
<!-- https://mvnrepository.com/artifact/org.seleniumhq.selenium/selenium-java -->
<dependency>
<groupId>org.seleniumhq.selenium</groupId>
<artifactId>selenium-java</artifactId>
<version>4.0.0-alpha-5</version>
</dependency>
4. 브라우저를 실행시켜서 사이트 접속과 html 가져오기
WebDriver 드라이버 = new 브라우저Driver(); // 브라우저 실행
드라이버.get(String url); //url에 접속
드라이버.getPageSource() // html 리턴
=> 위의 코드를 실행하기 전에 브라우저 설정
System.setProperty(String 브라우저드라이버이름, String 드라이버경로)
1) pom.xml 파일에 selenium 라이브러리를 설정하기 위한 의존성을 설정
 |
2) main 메소드에 작성
try {
// 크롬을 사용하기 위한 환경 설정
System.setProperty("webdriver.chrome.driver", "./chromedriver.exe");
// 크롬실행 객체 만들기
WebDriver driver = new ChromeDriver();
driver.get("http://www.naver.com");
driver.getPageSource();
}catch(Exception e) {
System.out.println("크롬 실행 실패");
System.out.println(e.getMessage());
e.printStackTrace();
}
3) 크롬의 경우 한 번 실행하면 최신 버전으로 업그레이드를 해서 드라이버를 최신버전으로 변경해야만 두번째 부터 실행된다.
8 교시
5. WebDriver 클래스의 메소드
=> get(String url) : url 에 접속
=> String getPageSource() : html을 리턴
=> close() : 브라우저 종료
=> element를 찾아오는 메소드
WebElement findElement(By.id(String id) 또는 By.xpath(String xpath))
WebElements findElements(By.tagName(String tag) 또는 By.class(String class))
=> 크롬을 실행하지 않고 작업을 수행
ChromeOptions 옵션 = new ChromeOptions();
옵션.addArguments("headless");
WebDriver 드라이버 = new ChromeDriver(옵션);
=> WebElement 에 데이터를 입력하거나 클릭한 효과
send_keys(String data) : 입력도구인 경우 data가 입력
click() : 버튼이나 a 태그인 경우 클릭한 효과가 나타남.
6. 다음의 자동 로그인
카카오로 다음 로그인하는 페이지 : https://accounts.kakao.com/login?continue=https%3A%2F%2Flogins.daum.net%2Faccounts%2Fksso.do%3Frescue%3Dtrue%26url%3Dhttps%253A%252F%252Fwww.daum.net%252F
=> 페이지가 frame으로 구성된 경우 frame의 데이터에는 직접 접근이 안된다.
frame :
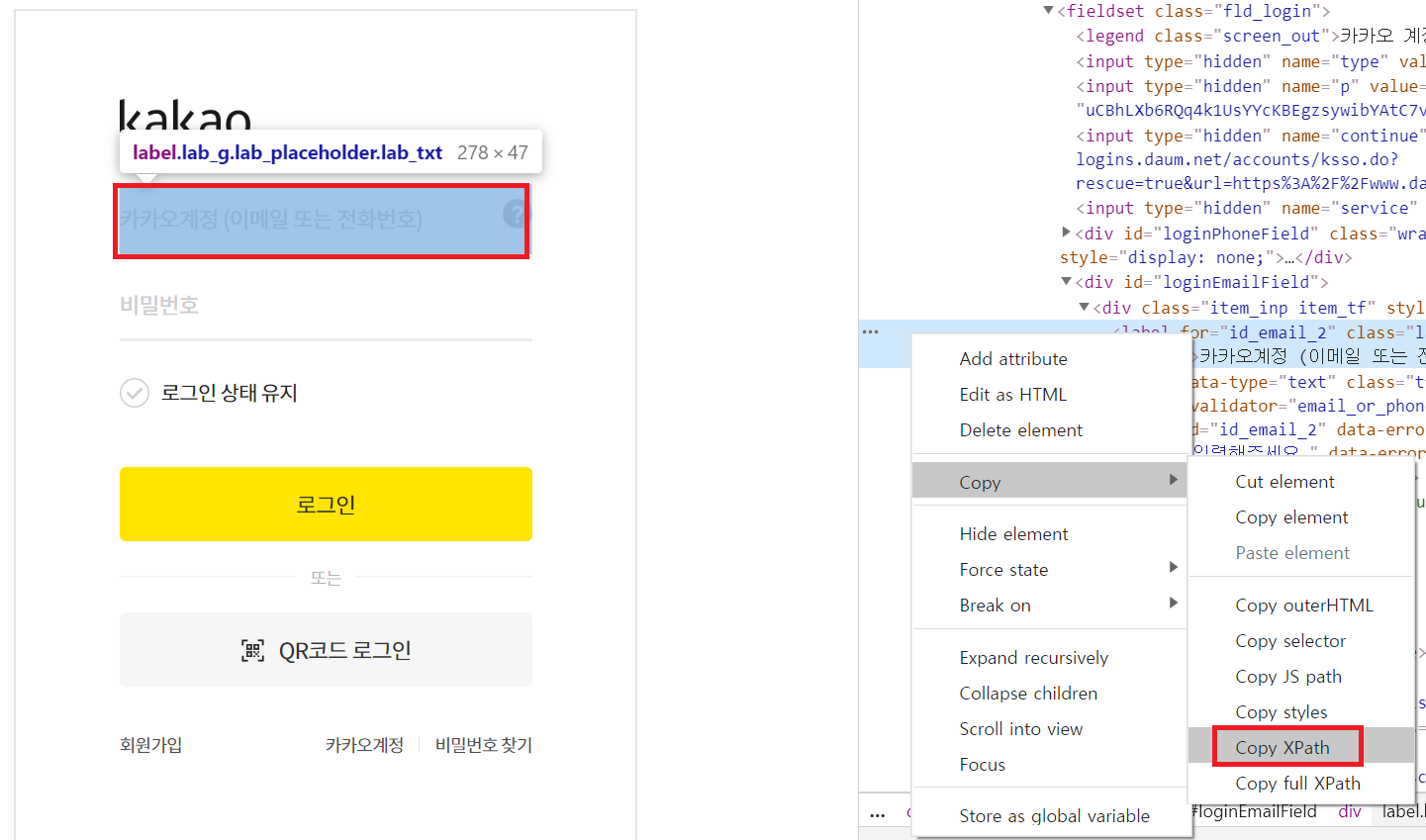 직접 xpath를 찾아야 한다. |
 |
 |
 |
package htmlparsing;
import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.chrome.ChromeDriver;
public class DaumCafeWriting {
public static void main(String[] args) {
try {
// 브라우저 실행
System.setProperty("webderiver.chrome.driver", "./chromedriver.exe");
// 브라우저 실행
WebDriver driver = new ChromeDriver();
// 다음 로그인 페이지 접속 - 카카오 로그인은 안되는듯 하다.
driver.get("https://accounts.kakao.com/login?continue="
+ "https%3A%2F%2Flogins.daum.net%2Faccounts"
+ "%2Fksso.do%3Frescue%3Dtrue%26url%3Dhttps%253A%252F%252F"
+ "www.daum.net%252F");
// 아이디 입력란을 찾기
WebElement id = driver.findElement(By.xpath("//*[@id=\"loginEmailField\"]/div/label"));
id.sendKeys("lsb5212@naver.com");
// 비밀번호 입력란 찾기
WebElement pw = driver.findElement(By.xpath("//*[@id=\"login-form\"]/fieldset/div[3]/label"));
id.sendKeys("");
// 로그인 버튼 찾기
WebElement login = driver.findElement(By.xpath("//*[@id=\"login-form\"]/fieldset/div[8]/button[1]"));
login.click();
// 페이지 이동이 많을 대는 과부하를 방지하기 위해서 중간중간 sleep을 추가
Thread.sleep(3000);
// 카페로 이동
driver.get("http://cafe.daum.net/dotax");
// 프레임으로 이동
driver.switchTo().frame("down");
//글을 입력
WebElement memo =
driver.findElement(By.xpath(
"//*[@id=\"memoForm__memo\"]/div/table/tbody/tr[1]/td[1]/div/textarea"));
memo.sendKeys("댓글을 입력합니다.");
//댓글 등록 버튼 클릭
WebElement write =
driver.findElement(By.xpath(
"//*[@id=\"memoForm__memo\"]/div/table/tbody/tr[1]/td[2]/a[1]/span[2]"));
write.click();
}catch(Exception e) {
System.out.println("다음 카페 글 쓰기 실패");
System.out.println(e.getMessage());
e.printStackTrace();
}
}
}