1 교시
** 자바에서 나중에 할 것 - 안드로이드 하기 전에 학습
=> 람다와 스트림
=> GUI Programming(AWT, SWING, GRAPHIC, Java FX 등)
=> Design Pattern : 자바 문법이 아니고 객체 지향 설계
** 외부 라이브러리 (3rd Party Library)
=> 자바에서 제공하지 않고 다른 개발자들이 만들어서 배포하는 라이브러리를 사용
1. Open Source
=> source code를 누구나 볼 수 있게 하고 이 source code를 수정해서 애플리케이션을 만들 수 있도록 한 것
1) Open Source 의 장점
=> 시간과 노동력이 감소
=> 직접 개발하는 것 보다는 성능이 우수할 가능성이 높다.
=> 신뢰성이 높음 : Linux, Python, R, Node.js 진영에서는 개발자들의 모임인 CRAN을 만들어서 Open Sourcr를 검증을 한 후 사용할 수 있도록 해준다.
그 전까지는 제조회사가 제공하는 코드만 사용하던지 검증되지 않은 코드들을 사용함으로 인한 위험성이 존재
2. Maven
=> java build tool
1) 프로그램 실행 과정
=> Source Code 작성 -> Class 생성(byte code - 중간 코드) : 이 과정을 Compile 이라고 한다. 이 때는 문법 검사를 수행해서 문법에 맞지 않는 경우 Class를 생성하지 않는다.
=> 개발자가 작성한 Class와 외부 라이브러리 Class들을 가지고 StartUp Code를 추가해서 실행 가능한 코드를 생성 : 이 과정을 Build라고 한다.
이 때는 문법 검사를 하지 않고 시작점이 어디인지 등을 확인
=> 실행 : Run
실제 데이터들의 값을 가지고 수행해서 값이 없거나 잘못되면 Exception을 발생시킨다.
2. Java의 Build Tool
=> Maven : pom.xml 에 기반한 방식 - XML 이용 - 예전에 Spring Project 같은 곳에서 많이 사용
=> Gradle : build.gradle에 기반한 방식 - JSON 이용 - Android Studio에서 사용
=> Legacy Project(우리나라의 경우 대기업이나 금융 또는 공공기관 프로젝트 - 전자정부 프레임워크)에서는 Maven을 많이 사용하고 Android 개발이나 소규모 Project에서는 gradle을 많이 사용
3) Build Tool이 있는 경우와 없는 경우의 차이
=> build tool이 없는 경우
외부 라이브러리를 다운로드
외부 라이브러리를 프로젝트에 추가
외부 라이브러리를 build path에 추가
=> build tool을 사용하는 경우
build tool이 제공하는 설정 파일에 외부 라이브러리 이름을 작성
build tool이 자신의 컴퓨터에서 외부 라이브러리가 있는지 찾아보고 없으면 다운로드해서 저장하고 프로젝트에 복사해서 build path에 추가를 해준다.
4) build tool의 장점
=> 외부 라이브러리의 버전 등이 변경된 경우에 buill tool을 사용하면 텍스트만 변경
=> 여러 개발자가 공통으로 작업하는 경우 설정 파일만 복사하면 동일한 환경에서 개발할 수 있다.
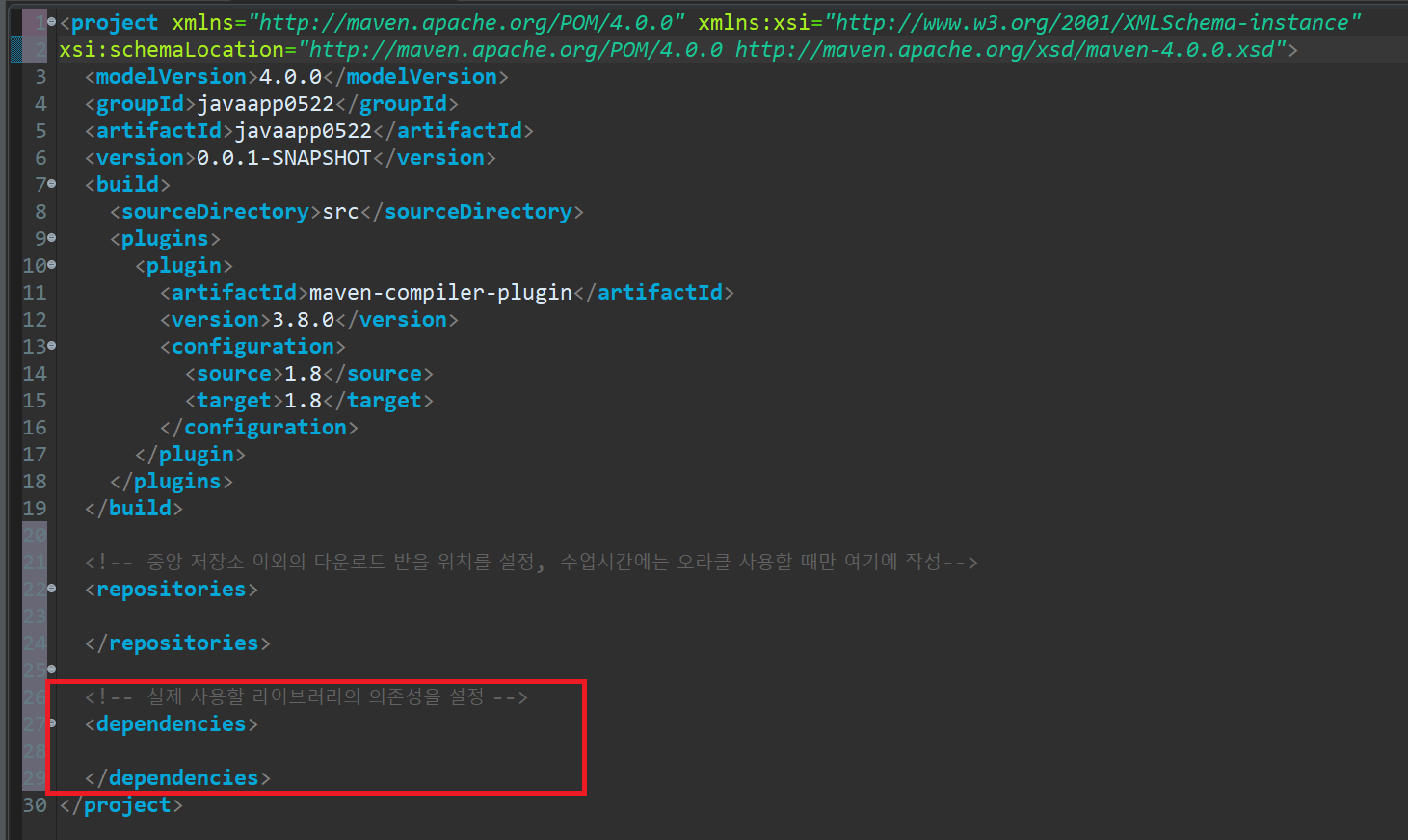
5) pom.xml
=> Maven 환경 설정 파일
=> Maven 기반의 프로젝트에서는 가장 먼저 수행
=> repositories : 외부 라이브러리를 다운로드 받을 저장소를 설정
설정하지 않으면 Maven Central Repository에서 다운로드
기업에서는 아무 라이브러리나 사용할 수 없어서 기업 내의 repository를 만들고 라이브러리를 다운로드 받는다.
CDN : Content Delivery Network - 라이브러리를 모아놓은 네트워크
수업시간에는 오라클을 사용할 때만 설정
=> dependencies : 실제 사용할 라이브러리를 설정
=> 자바 외부 라이브러러의 maven dependency 나 gradle의 dependency를 검색할 수 있는 사이트
Maven Repository: Search/Browse/Explore
Event sources for AWS Lambda Last Release on May 21, 2020
mvnrepository.com
2~3 교시
7) MySQL 드라이버를 로드하는 코드를 작성
|
package javaapp0522; public class MySQLDriverLoad { public static void main(String[] args) { } } // 에러 |
8. 프로젝트를 Maven 프로젝트로 변환
=> 프로젝트를 선택하고 우클릭
[Configure] - [Convert to Maven Project]
 |
 |
 |
=> 프로젝트 이름 상단에 M이 보임 : Maven Project
=> pom.xml 파일이 추가
9. pom.xml 파일에 mysql 의존성(라이브러리를 가져와서 build path에 추가)을 추가
 |
 |
 |
 |
 붙여넣기 하면 작성된다. |
| 그 이후에 메인을 다시 실행하면 드라이버 로드 성공 |
=> 이전에는 드라이버 파일을 다룬도르 받아서 프로젝트에 복사하고 build path에 추가햇는데 maven에서는 pom.xml 파일에 작성만 하면 된다.
10) maven의 외부 라이브러리 사용 원리
=> pom.xml의 dependencies 태그를 보고 필요한 라이브러리를 확인
=> 자산의 계정/.m2 라는 디레고텔세서 라이브러리가 있는지 확인하고 없으면 다운로드
Mac이나 Linux에서는 앞에 .이 붙으면 숨김 디렉토리
Mac에서는 Shift + Command + . 을 눌러야만 확인이 가능
=> 다운로드 받은 파일을 프로젝트에 복사한 후 build path에 추가한다.
11) Maven 오류
=> Mavan 프로젝트를 만들었는데 가장 상단의 태그에서 plug-in 오류가 발생하는 경우
pom.xml 파일의 dependencies 태그에 추가
| dependencies에 아래 코드를 추가 <dependency> <group>org.apache.maven.plugins</groupId> <actifactId>maven-resource-plugin</artifactId> <version>2.4.3</version> </dependency> 프로젝트를 선택한 후 마우스 오른쪽 클릭 > Run As > Maven Install 프로젝트를 선택한 후 F5(새로고침) 프로젝트를 선택한 후 마우스 오른쪽 클릭 > Maven > Update Project |
=> dependency에 오류가 발생한 경우 : 중앙저장소에 없거나 잘못된 의존성을 설정
중앙저장소를 설정하거나 의존성을 수정
=> 의존성에는 에러가 없는데 프로그램을 실행하면 클래스가 없다고 에러나는 경우
다운로드를 제대로 받지 못해서 생긴 에러
2. JavaDoc
=> 자바 개발 문서를 만드는 기능
=> JavaDoc 주석을 만들 때는 /** 로 시작
=> 주석을 만들면 Eclipse에서 마우스를 가져다 놓으면 툴팁으로 메시지를 출력
=> 클래스와 필드 그리고 메소드에 모두 주석을 만들 수 있다.
[Project] - [Generate Javadoc]를 클릭
 |
 |
명령어를 이용해서 생성 - 한글이 없으면 javadoc -접근지정자 "소스파일"
javadoc -private -encoding UTF-8 -charset utf-8 -docencoding UTF-8 "소스파일

|
 클릭 |
 개발문서 파일이 생성되었다. |
javadoc -d docs *.java : 디렉토리 안의 모든 자바 파일의 doc을 생성
4 교시
3. CheckStyle
=> 자바의 기본 규칙에 맞지 않게 작성된 코드에 경고를 표시해주는 라이브러리
1) plug-in 설치
=> [Help] - [Eclipse MarketPlace] 에서 CheckStyle plug-in으로 검색해서 설치
 |
2) 사용
=> 프로젝트를 선택하고 마우스 우클릭 후 [Properties]를 선택
=> CheckStyle 탭을 선택하고 오른쪽 창에서 프로젝트에 활성화한다는 메뉴를 선택
 |
 노란색으로 규칙에 안맞는 걸 표시해준다. |
4. JUnit
=> 단위 테스트를 위한 라이브러리
=> Unit Test : 프로그램을 구성하는 기본 단위 프로그램이 정상적으로 동작하는지 테스트
=> TDD(Test Driven Development) : 테스트 주도 개발
프로그램을 구성하는 부분을 먼저 테스트해보고 구현
1) Eclipse에서 사용할 수 있도록 설정
=> 프로젝트 선택하고 마우스 우클릭 [Properties]
Java Build Path를 선택하고 오른쪽 창에서 Add Library 버튼을 누르고 JUnit을 선택

|
 |
2) 사용
=> TestCase로부터 상속받는 클래스를 만들고 메소드를 생성해도 되고 일반 클래스에 메소드를 만들고 위에 @Test를 추가해도 된다.
3) 실행
=> 메소드 위에서 마우스 우클릭 [Rus As] - [JUnit Test]를 선택 포트폴리오 만들때 꼭 집어넣어라
 |
5 교시
5. CSV(Comma-Separated Values)
=> 콤마만 가지고 데이터를 구분해서 표현하는 방식
=> 콤마만 가지고 하다가 최근에는 공백, 탭, 엔터 등을 이용하기도 한다.
=> 일정한 간격을 가지고 데이터를 구분하면 fwf(fixed width file)이라고 한다.
=> 구분자를 데이터로 사용하고자 하는 경우에는 "로 감싸면 된다.
=> 변하지 않는 데이터를 제공해주고자 할 때 많이 사용하는 포맷이다.
=> split 메소드를 이용해서 직접 파싱하는 것도 가능하지만 대부분 외부 라이브러리를 이용한다.
=> java의 csv관련 외부라이브러리로 많이 사용되는 것은 Super csv
CsvBeanReader 인스턴스를 생성 : 매개변수로 csv 파일의 Reader 객체와 환경 설정 옵션을 대입
CsvBeanReader ? = new CsvBeanReader(new BufferedReader(new InputStreamReader(new FileInputStream())), CsvPreferences.STANDARD_PREFERENCE);
- 헤더 만들기 : DTO클래스의 프로퍼티 이름과 같아야 한다.
String [] 헤더 = {직접 작성};
?.getHeader(true);
1) 현재 프로젝트에 vollyball.csv 파일일 생성하고 작성
name,birth,email.nickname,age
배유나,1989-11-30,bae@xxx.co.kr,"배구천재",32
문정원,1992-03-04,moon@xxx.co.kr,"문라이트".29
2) super-csv를 사용하기 위한 의존성을 추가
=> www.mvnrepository.com 에서 서 검색해서 사용
=> pom.xml파일의 dependecies 에 추가
3) 한 줄의 데이터를 저장할 DTO 클래스를 생성
4) Main 메소드를 소유한 클래스를 만들어서 csv파일의 내용을 읽어서 출력
 |
 결과가 한글이 깨진 상태로 나오는데 csv 파일이 ANSI 로 인코딩되어 있어서다. |
 이렇게 UTF-8로 저장후 다시 실행하면 |
 한글이 제대로 출력된다. |
6~7 교시
- 데이터 읽어오기
제약조건을 생성 - 각 열의 제약조건 설정
필수 : new NotNull()
선택 : new Optional()
정수 : new ParseInt()
날짜 : new ParseDate("날짜서식")
CellProcessor [] 제약조건배열 = new CellProcessor[] {
};
앞에서 만든 reader 객체.read(DTO클래스.class, 열이름배열, 제약조건)을 호출하면 DTO클래스의 인스턴스를 순서대로 리턴하는데 더 이상 읽을 데이터가 없으면 null을 리턴
|
package javaapp0522; import java.io.BufferedReader; import org.supercsv.cellprocessor.Optional; public class CSVMain { public static void main(String[] args) { } } |
** Data Parsing Project
=> Maven Project로 변환
프로젝트를 선택하고 마우스 우킬륵 후 [Configure] - [Convert to Maven Project]를 클릭
=> 확인
프로젝트 이름 왼쪽 상단에 M이 표시, pom.xml이 생성됨
1. csv 읽기
1) pom.xml 파일에 csv파일
=> www.mvnrepository.com에서 super-csv를 검색
2) 데이터 파일의 인코딩을 확인
=> utf-8이 아니면 파일의 인코딩을 변경해서 저장
3) 파일을 정상적으로 읽는지 확인
 |
4) 데이터 구조 파악
=> 첫번째 줄이 데이터인지 아니면 컬럼이름인지 확인
첫번재 줄이 데이터가 아님 - 구분,살인,강도,강간·추행,절도,폭력
첫번째 줄이 아니면 첫번째 줄은 데이터가 아니라고 가르쳐 줘야함
CsvBeanReader객체.getHeaders(true);
=> 각 컬럼이 자료형이 무엇인지 그리고 몇 개인지 확인 - 6개
구분 String
살인 int
강도 int
강간·추행 int
절도 int
폭력 int
=> 컬럼의 이름을 변수명으로 사용할 것인지 아니면 새로운 이름을 부여할 것인지 결정
5) DTO (Data Transfer Object) 클래스를 생성
|
package dataparsing; public class Crime { } |
 |
6) main 메소드에서 데이터를 읽는 부분 추가
|
package dataparsing; import java.io.BufferedReader; import org.supercsv.cellprocessor.Optional; public class CSVRead { public static void main(String[] args) { } } |
| 구별 절도 숫자가 출력된다. |