1 교시
** 데이터베이스 사용
1. 데이터베이스 서버
=> 서버의 IP : 자신의 컴퓨터인 경우는 localhost
192.168.0.200
=> 서비스의 포트번호 : 1521(오라클의 기본포트 - 8080번 포트도 사용)
=> 사용 가능한 데이터베이스 이름 : SID -xe
오라클 최신 버전은 SID 대신에 Service Name을 기본으로 사용
=> 계정 : 아이디 - user01 ~ user20
=> 비번 : user01 ~ user20
2. 데이터베이스 접속 프로그램 - DBeaver
=> 다른 프로그램을 사용하는 경우도 많음
=> 접속하고자 하는 데이터베이스의 자바 드라이버가 필요

** select
1. 기본형식
select [distinct] * 또는 컬럼이름 나열
from 테이블이름
where 조건
=> 테이블에서 조건에 맞는 컬럼을 조회
distinct는 중복을 제거
*을 사용하면 모든 열이 조회
=> select와 from은 생략이 불가능
=> where절을 제외한 부분은 대소문자 구분을 하지 않는다. (where절만 대소문자 구분을 한다)
ex1) emp 테이블에서 sal이 1500 이상인 데이터의 모든 열을 조회
SELECT *
FROM EMP
WHERE sal >=1500;

ex2) emp 테이블에서 job이 MANAGER인 데이터의 empno, ename, job을 조회
SELECT EMPNO , ename , job
FROM EMP
WHERE JOB = 'MANAGER';

2. 패턴일치
=> like
=> 2개의 wildcard 문자를 이용
_ : 무조건 1글자
% : 0글자 이상
a_ : a로 시작하는 2글자
a% : a로 시작하는 모든 것
ex1) emp 테이블에서 ename이 M으로 시작하는 데이터의 ename, job을 조회
SELECT ENAME , job
FROM EMP
WHERE ENAME LIKE 'M%';

ex2) emp 테이블에서 ename에 R이 포함된 데이터의 ename, job을 조회
SELECT ENAME , job
FROM EMP
WHERE ENAME LIKE '%R%';

ex3) emp 테이블에서 hiredate('yyyy-mm-dd')가 1982년인 데이터의 ename, job, hiredate을 조회
SELECT ENAME , job, hiredate
FROM EMP
WHERE HIREDATE LIKE '82%';

ex4) emp 테이블에서 ename에 T가 2개 이상 포함된 데이터의 ename, sal, job을 조회
SELECT ENAME , sal, job
FROM EMP
WHERE ENAME LIKE '%T%T%';

2~3 교시
3. null 값 조회
=> is null 로 조회
=> = null 로 조회하면 null 이라는 문자열을 가지고 있는 데이터를 조회
ex) emp 테이블에서 comm의 값이 null 인 데이터의 모든 열을 조회
SELECT *
FROM EMP
WHERE COMM IS NULL;

4. and, or, not
=> and 는 2개의 조건을 모두 만족
=> or 는 2개의 조건 중 하나만 만족
=> not 은 반대로
not between
not in (데이터 모임)
not like 패턴
is not null
item 테이블에서 name에 바나나 우유가 포함된 데이터를 조회
selent *
from item
where name like '%바나나 우유%'; or name like '%바나나%' and name like '%우유%';
String search = "LG 노트북";
String [] ar = search.slpit("");
select *
from 테이블이름
where item like '%ar[0]%' and item like '%ar[1]%';
=> and 가 or 보다 먼저
ex) emp 테이블에서 ename에 t가 포함되지 않고 job이 MANAGER인 사원의 ename, job, sal 의 값을 조회
SELECT ENAME , job, sal
FROM EMP
WHERE ENAME NOT IN '%t%';

select
from
where
order by 정렬기준 [ASC | DECS], 정렬기준 [ASC | DESC]...
=> order by 절에 정렬할 기준을 설정하면 된다.
=> order by는 select 다음에 마지막으로 수행되기 때문에 select에서 만든 별명을 사용할 수 있다.
=> 정렬 기준을 설정할 때 select에 기재한 열 이름의 인덱스를 기재해도 가능
=> ASC나 DESC를 생략하면 ASC(오름차순)
=> 2개 이상의 정렬 기준을 설정하면 앞의 정렬 기준이 우선하고 그 값이 동일할 때 뒤의 정렬 기준이 적용된다.
=> 데이터를 조회할 때 2개 이생의 행이 리턴된다면 특별한 경우가 아니라면 정렬을 해서 출력을 해야한다.
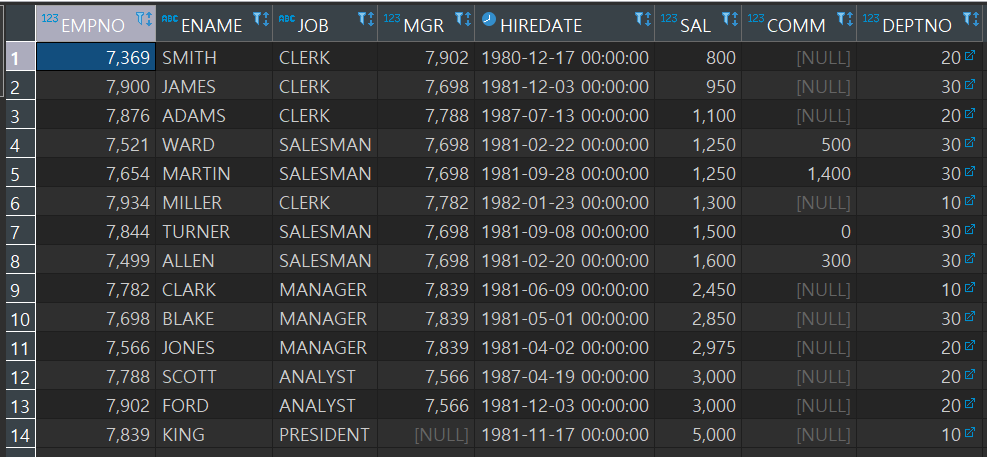
ex1) emp 테이블에서 sal의 내림차순으로 모든열을 조회
SELECT *
FROM EMP
ORDER BY sal DESC

ex2) emp 테이블에서 job의 오름차순으로 조회하고 job이 같은 경우는 sal의 오름차순으로 모든 열을 조회
SELECT *
FROM EMP
ORDER BY sal DESC , sal ASC;
4 교시
** 오라클의 단일행 함수
1. 오라클의 함수
=> 리턴값이 있는 코드의 모임
=> 종류로는 단일행 함수와 그룹 함수로 분류
=> 단일행 함수는 하나의 데이터를 가지고 연산을 해서 하나의 결과를 리턴하는 함수
여러 개의 데이터를 함수에 대입하면 함수는 각각의 데이터에 동작을 해서 결과를 여러개로 리턴한다.
2. 개발자 입장에서는 데이터베이스에서 데이터를 가공하는 것보다는 프로그램 안에서 가공하는 것을 선호
3. DUAL 테이블
=> 오라클의 가상 테이블
=> 연산식이나 오늘 날짜 , sequence 등의 값을 알고자 할 때 사용할 수 있는 가상 테이블
=> 12*30*24의 값을 조회
select 12*30*24 이렇게만 쓰면 에러 from이 필수이기 때문
select 12*30*24
from dual;
4. ROUND
=> 데이터를 반올림해주는 함수
=> 숫자 데이터와 날짜 데이터에 사용이 가능
Round(데이터, 반올림할 자리)
=> 자리를 생략하면 0가 설정되서 소수 첫째 자리에서 반올림
=> 음수를 대입하면 정수 부분을 반올림
ROUND(123.87, 1) : 123.9
ROUND(123,87) : 124
ROUND(123,-2) : 100
ex) emp 테이블에서 ename과 sal을 조회
sal의 값은 10의 자리에서 반올림해서 100의 자리까지 나오도록 출력
SELECT ename, ROUND(SAL, -2)
FROM EMP;

5. 문자 관련 함수
=> 영문자를 사용할 대는 대소문자 구분 여부를 판단 : UPPER, LOWER, INICAP
=> 문자열의 길이 : LENGTH(글자개수), LENGTHB(바이트 수 )
대다수의 교재들이 한글이 2Byte라고 하지만 지금 사용하고 있는 UTF-8 인코딩에서는 한글 1글자는 3Byte이다.
=> 좌우 공백을 제거하는 부분도 고민해야 한다. : LTRIM, RTRIM, TRIM
데이터를 생성할 때 입력 가능한 최대 글자 수로 설정을 하기 때문에 뒤에 공백이 있을 수 있다.
ex1) 글자 수 와 바이트 수 확익
select length('WIRERESS'), lengthb('AIRPODPRO'), length('무선이어폰'), lengthb('무선이어폰')
from dual;

ex2) emp 테이블에서 job이 manager 인 사원의 ename 과 job, sal을 조회
SELECT ENAME , JOB , sal
FROM EMP
WHERE lower(job) = 'manager';

6. 형 변환 함수
=> 데이터의 자료형 변환
=> 문자 데이터와 숫자 및 날짜 데이터 사이의 변환
=> 사용자의 입력을 받거나 프로그래밍 언어로부터 입력받을 때는 문자열로 입력받고 실제 사용을 할 때는 변환해서 사용하는 경우가 많다.
1) to_char
=> 날짜 데이터를 문자열로 변환하고자 하는 경우
to_char(날짜 데이터, '출력 서식')
to_char(숫자 데이터, '출력 서식')
2) to_number
to_number(문자 데이터, '숫자 서식')
3) to_date
to_date(문자 데이터, '날짜 서식')
ex) 1986년 5월 5일 오후 1시를 날짜로 생성
select to_date('1986-05-05 13', 'yyyy-mm-dd hh24')
from dual;

7. 날짜
1) 현재 시간
=> sysdate
2) 오라클에서는 하루를 숫자 1로 판단
3) 날짜 데이터와 정수 간의 연산을 지원
+ 와 - 만 의미
4) 날짜 데이터끼리 뺄셈도 지원
5) ROUND, TRUBNC, FLOOR 와 같은 숫자 데이터함수에 날짜 데이터 사용 가능
ex) emp 테이블에서 각 사원의 근무일수를 조회
ename과 근무일수 조회
입사일은 hiredate에 저장되어 있다.
SELECT ename, ROUND(SYSDATE-HIREDATE) 근무일수
FROM EMP;

5 교시
8. NVL
=> null 값을 치환하기 위한 함수
=> null 은 아직 알려지지 앟은 값 - 자료구조에서는 nil 이라고 하디고 한다.
=> null 과의 산순 연산의 결과는 null
=> null 과는 연산을 할 수 없기 때문이다.
=> null 인 데이터의 값을 치환하기 위해서 사용하는 함수가 NVL 이고 형식은 아래와같음
nvl(표현식 또는 열이름, 대체할 값)
=> 대체할 값은 열이름의 자료형과 일치해야 한다.
ex) comm 열에 null 값이 포함되어 있다.
comm 열을 가지고 산술 연산을 하면 결과는 null
이런 경우에는 null 값을 다른 값으로 대체해서 연산을 수행해야 한다.
대체를 할 때는 제거하고 연산을 하기도 하고 빈번히 나오는 값 또는 평균, 중간값, 0, 미선러닝에 의한 값 등으로 대체해서 작업
emp 테이블에서 ename, sal * 12 + comm 의 값을 조회
comm의 값이 null 이면 0으로 대체해서 연산
select ename, sal * 12 + nvl(comm, 0)
from emp;

** Group Function
=> 하나 이상의 행을 묶어서 연산한 결과를 리턴하는 함수
1. 함수 종류
1) count : 데이터 개수
2) sum : 데이터 합계
3) avg : 평균
4) max : 최대값
5) min : 최소값
========데이터의 분포를 알아보기 위한 함수 ======
6) stddev : 표준편차 (분산의 제곱근)
7) variance : 분산 (값-평균을 뺀 값을 제곱해서 더한 값)
2. SUM, AVG, MAX, MIN
=> NULL 값을 제외하고 연산
=> AVG 는 NULL 을 제외하고 계산하는 것과 포함하고 계산하는 결과가 달라진다.
ex) emp 테이블에서 comm의 평균을 조회
select avg(comm)
from emp;

=> comm이 NULL이 아닌 데이터가 4개가 있으므로 4개의 평균을 구한다.
select avg(nvl(comm,0))
from emp;
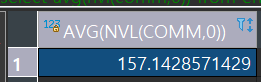
=> comm이 NULL인 데이터의 값을 0으로 해서 14개의 평균을 구한다.
3. COUNT
=> NULL을 제외한 행의 개수를 리턴하는 함수
=> 다른 함수들은 컬럼 이름을 매개변수로 대입하지만 COUNT의 경우는 컬럼이름 대신에 *을 입력하기도 한다.
ex) emp 테이블의 데이터 개수 세기
select count(*)
from emp;

=> 데이터가 많아서 페이지 단위로 나누어 출력하고자 하는 경우 이 SQL을 실행해서 몇 개의 데이터인지 확인하고 페이지 당 출력 개수로 나누어서 몇 개의 페이지를 생성해야 하는지 계산을 수행해야 한다.
ex2) EMP 테이블에서 job의 개수 조회
SELECT COUNT(DISTINCT JOB) // 중복도 제거
FROM EMP;

ex3) EMP 테이블에서 COMM이 NULL 인 데이터의 개수 조회
SELECT COUNT(*) // COUNT(COMM)으로 하면 0개로 출력된다. 그러므로 *을 사용하자.
FROM EMP
WHERE COMM IS NULL;

4. 그룹함수는 그룹화하지 않은 열과 같이 출력할 수 없다.
=> EMP 테이블에서 SAL 가장 큰 데이터의 ENAME과 SAL의 값을 조회
SELECT ENAME, MAX(SAL) --ENAME을 그룹화 하지 않았기 때문에 에러
FROM EMP;
5. GROUP BY
=> WHERE 절 다음에 기재해서 데이터를 그룹화하는 절
=> 컬럼이름이나 표현식 모두 가능
=> GROUP BY를 사용하는 경우 GROUP BY에서 그룹화 한 열과 그룹함수인 SELECT 구문에서 조회할 수 있다.
EX1) EMP 테이블에서 JOB별로 SAL의 평균을 조회
SELECT JOB, AVG(SAL)
FROM EMP
GROUP BY JOB ;

EX2) EMP 테이블에서 DEPTNO 별 인원수 조회
SELECT DEPTNO, COUNT(*)
FROM EMP
GROUP BY DEPTNO;

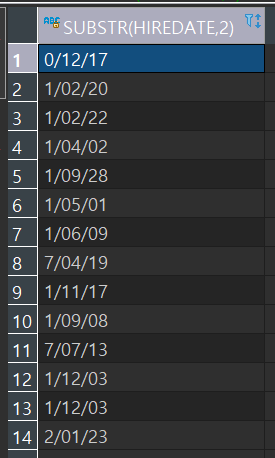
EX3) 년도별 입사한 사원의 수를 조회
--SUBSTR(데이터, 시작위치, 개수), 개수를 생략하면 끝까지 가져온다.
SELECT SUBSTR(HIREDATE, 1, 2), COUNT(*)
FROM EMP
GROUP BY SUBSTR(HIREDATE, 1, 2)
ORDER BY SUBSTR(HIREDATE, 1, 2);
ex4) 요일별로 입사한 사원수 조회
SELECT TO_CHAR(HIREDATE, 'dy'), COUNT(*)
FROM EMP
GROUP BY TO_CHAR(HIREDATE, 'dy');

6. HAVING
=> GROUP BY 이후의 조건
=> WHERE는 GROUP BY 이전에 수행되기 때문에 그룹화 한 이후의 조건 설정에는 사용할 수 없다.
6. SELECT의 구조 (암기)
5- SELECT 조회할 열 이름이나 표현식 나열 또는 *
1- FROM 조회할 테이블 이름
2- WHERE 조회할 조건
3- GROUP BY 그룹화할 열 이름이나 표현식
4- HAVING 그룹화 한 이후의 조건
6- ORDER BY 정렬할 열이름 이나 표현식
=> GROUP 함수는 GROUP BY 절을 넘어가야만 사용이 가능(암기)
6~7 교시
EX) EMP 테이블에서 JOB별로 SAL의 평균을 조회
JOB에 종사하는 인원수가 3명 이상인 경우만 조회
SELECT JOB, ROUND(AVG(SAL)) -- 소수점 생략
FROM EMP
GROUP BY JOB
HAVING COUNT(*) >= 3
ORDER BY JOB; -- 정렬

연습문제
=> EMP 테이블에서 HIREDATE의 년도 별 데이터 개수, SAL의 최소값, SAL의 최대값,SAL의 평균, SAL의 합계를 조회
데이터는 년도의 오름차순으로 조회
평균은 소수 첫째 자리까지만 조회
=> 년도 별로 묶을 때는 SUBSTR이나 TO_CHAR 함수를 이용
SELECT TO_CHAR(HIREDATE, 'YY'), COUNT(*), MIN(SAL), MAX(SAL), ROUND(AVG(SAL),1) "AVG(SAL)", SUM(SAL)
FROM EMP
GROUP BY TO_CHAR(HIREDATE, 'YY')
ORDER BY TO_CHAR(HIREDATE, 'YY') ASC;

8 교시
** JOIN (인터뷰에서 JOIN, TRANSACTION을 물어본다)
=> 2개 이상의 테이블에서 데이터를 조회하는 것
1. Cross Join
=> Cartesian Product 라고도 함
=> 2개 테이블의 모든 조합이 생성
=> 열의 개수는 2개 테이블의 열의 개수의 합
행의 개수는 2개 테이블의 행의 개수의 곱
=> from 절에 테이블 이름을 2개 기재하면 Cross Join이 된다.
emp 테이블은 8열 14행
dept 테이블은 3열 4행
Cross join 하면 11열 56행
ex) emp 테이블과 dept 테이블의 CROSS JOIN
SELECT *
FROM emp, dept;
사진생략
2. Inner Join
=> 2개 테이블의 공통된 의미가 있는 열이 있을 때 수행가능한 Join
=> where 절에 2개 테이블의 공통된 의미가 있는 열의 값이 같은 경우에만 결합을 하도록 하는 Join으로 Equi Join이라고도 한다.
EMP 테이블의 DEPTNO는 부서번호이고 DEPT테이블의 DEPTNO도 부서 번호이다.
ex) emp 테이블과 dept테이블을 deptno 열을 가지고 Inner Join
select *
form emp, dept
where eml.deptno = dept.deptno;
=> 양쪽 테이블에 동일한 이름이 열이 있을 때는 테이블 이름을 앞에 명시해주어야한다.
그렇지 않으면 열의 이름이 애매모호하다고 에레 메시지를 출력
3. Outer Join
=> 어느 한쪽 테이블에만 존재하는 데이터도 Join에 참여하는 것
=> 왼쪽 테이블에 있는 데이터가 참여하면 Left Outer Join이라고 하고 오른쪽 테이블에 있는 데이터가 참여하면 Rigft Outer Join이라고 한다.
=> Join조건을 만들 때 참여하고 싶은 테이블의 컬럼 뒤에 (+)을 붙이면 된다.
=> 표준 SQL에서는 (+)를 한쪽에만 붙여야 한다.
emp 테이블의 deptno는 10, 20, 30이 존재
dept 테이블의 deptno는 10, 20, 30, 40이 존재
ex) emp 테이블과 dept 테이블의 outer JOIN
-dept 테이블에는 존재하고 emp 테이블에 존재하지 않는 데이터도 참여
select *
FROM emp, dept
where emp.deptno(+) = dept.deptno;
'Oracle' 카테고리의 다른 글
| 25일차 공부 Transaction, DTO&DAO, Procedure (0) | 2020.05.13 |
|---|---|
| 24일차 공부 select, procedure, JDBC (0) | 2020.05.12 |
| 23일차 공부 Transaction (0) | 2020.05.11 |
| 22일차 공부 SELF JOIN, ANSI JOIN, SUB QUERY (0) | 2020.05.08 |
| 20일차 공부 Datebase, Oracle, select (0) | 2020.05.06 |



